

Why Is It Most Important To Pre-register Your Statistical Analyses?
A meta-analysis is a statistical integration of evidence from multiple studies that address a mutual enquiry question. By extracting effect sizes and measures of variance, numerous outcomes can be combined to compute a summary effect size. Meta-analyses are commonly used to back up enquiry grant applications, treatment guidelines, and wellness policy. Moreover, meta-analytic outcomes are ofttimes used to summarize a inquiry area in an endeavour to better direct future work. At that place is growing involvement in using meta-analysis inside the psychological sciences (Figure 1). This trend is probable to proceed given exponential increases in published enquiry (Bornmann and Mutz, 2015) and the wider availability of software and scripts for computing meta-analyses. Prior treatments have outlined the protocol (Shamseer et al., 2015) and pre-registration (Stewart et al., 2012) process, the theory behind conducting meta-analysis with vignettes (Viechtbauer, 2010), and guidelines for reporting meta-assay (Moher et al., 2009). However, it appears these approaches have yet to exist combined in a single resource targeting psychological scientists.
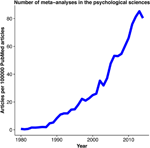
Effigy 1. Meta-assay in the psychological sciences. An illustration of the increasing interest in performing meta-analyses in the psychological sciences. PubMed data was collected on the number of articles containing the search terms "psychology" and "meta-analysis" published between 1980 and 2014 per 100,000 PubMed articles. Data was nerveless using the 'RISmed' R package.
The goal of this article is to provide a brief non-technical primer to guide the reader through this process, from pre-registration to the publication of results. Over half of the 25 journals that publish the most meta-analyses in psychology (Figure ii) recommend the use of the Preferred Reporting Items for Systematic Reviews and Meta-Analyses guidelines (PRISMA; Moher et al., 2009), or the related Meta-Analysis Reporting Standards (MARS; APA, 2008). Therefore, this review will demonstrate how to conduct a meta-assay post-obit PRISMA guidelines. Example analyses will be demonstrated using packages within the freely bachelor R statistical environment (R Evolution Core Team, 2015). Performing a meta-analysis with R tin appear daunting to those accustomed to "point and click" statistical environments such equally SPSS and SAS. Thus, a supplementary step-past-stride script illustrating the analytic procedures described in this newspaper, which requires only a rudimentary understanding of R, has been provided. Ultimately, the intention of this commodity is to improve understanding of meta-analytical procedures, and also amend prepare the reader to evaluate published meta-analyses. For a more in-depth and technical treatment of step-by-step meta-analysis methods, a range of first-class resource are available (Lipsey and Wilson, 2001; Hunter and Schmidt, 2004; Cooper, 2009).
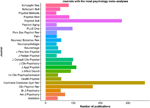
Effigy ii. Psychology journals that publish the greatest number of meta-analyses. The number of publications containing the keywords "psychology" and "meta-analysis" for the 25 journals with the nigh meta-analysis in psychology. Data was collected using the 'RISmed' R package.
Meta-analysis Protocol and Pre-registration
The main benefits of pre-registering a meta-analysis protocol are twofold. Firstly, the pre-registration procedure compels the researcher to codify a study rationale for a specific research question, which is the foundation of a expert systematic review (Counsell, 1997). Secondly, pre-registration helps avoids bias by providing evidence of a priori analysis intentions. Similar other types of empirical research, meta-assay is susceptible to hypothesizing after the results are known, otherwise known as "HARKing" (Kerr, 1998). In the case of meta-analysis, inclusion criteria can exist adjusted after results are known to accommodate sought-later results or reduce evidence of publication bias. Alternatively, the analysis could be left unpublished due to non-pregnant results (Tricco et al., 2009). These issues are particularly relevant if researchers have a fabric or intellectual conflict of interest. Pre-registration of clinical trials is a requirement for submission to most all peer-reviewed journals; however, few journals explicitly crave meta-analysis registration. Indeed, the pre-registration of meta-assay is arguably more of import than clinical trial pre-registration as meta-analyses are often used to guide handling practice and health policy.
The PRISMA protocol (PRISMA-P) guidelines (Shamseer et al., 2015) provide a framework for reporting meta-analysis protocols. These guidelines recommend that protocols include details such as report rationale, study eligibility criteria, search strategy, moderator variables, risk of bias, and statistical arroyo. As meta-analyses are iterative processes, protocols are likely to change over time. Indeed, over 20% of meta-analyses make changes to original protocols (Dwan et al., 2011). By having a record of a protocol prior to analysis, these changes are transparent. Whatsoever deviations from the original protocol tin exist stated in the methods section of the paper. Study protocols can be submitted as preprints (eastward.thou., PeerJ PrePrints, Open Science Framework, bioRxiv) or submitted as a peer-reviewed article to open up access journals that take study protocols (e.m., BMC Psychology, Systematic Reviews). Meta-analyses tin can also exist registered in the PROSPERO database1, which guidelines formed the ground for the PRISMA-P checklist. In addition to the PRISMA-P guidelines, online resource are available that provide information on meta-assay pre-registration specific to social science2 and medicine3. Although nearly journals do non explicitly state that meta-analysis registration is a requirement, many require the submission of a PRISMA checklist, which includes a protocol and report registration. Additionally, pre-registration may assistance avoid unintended meta-assay duplication. Checking whether other researchers are in the process of conducting a like meta-analysis can potentially save valuable resource.
Literature Search and Data Drove
Ane of the virtually important steps of a meta-analysis is data collection. For an efficient database search, appropriate keywords and search limits need to be identified. Key articles will exist overlooked if these search terms are too narrow. On the other hand, overly broad search terms will return a big book of literature that may be irrelevant for the analysis. Nonetheless, information technology is meliorate to slightly overshoot the marker to avoid missing of import articles. The use of Boolean operators and search limits can assist the literature search (for examples, see Sood et al., 2004; Vincent et al., 2006). A number of databases are bachelor (e.thousand., PubMed, Embase, PsychInfo), still, it is upward to the researcher to choose the about appropriate sources for their inquiry expanse. Indeed, many scientists use duplicate search terms within 2 or more databases to cover multiple sources. The reference lists of eligible studies can also be searched for eligible studies (i.e., snowballing). The initial search may return a large volume of studies. Quite ofttimes, the abstract or the championship of the manuscript reveals that the report is non eligible for inclusion, based on the pre-specified criteria. These studies can be discarded. Yet, if information technology appears that the report may be eligible (or even if there is some doubt) the total paper can be retained for closer inspection. The references lists of eligible manufactures tin can also exist searched for any relevant articles. These search results demand to exist detailed in a PRIMSA flow diagram (Moher et al., 2009), which details the menses of data through all stages of the review. Thus, it is of import to notation how many studies were returned after using the specified search terms and how many of these studies were discarded, and for what reason. The search terms and strategy should be specific plenty for a reader to reproduce the search. The date range of studies, forth with the date (or engagement period) the search was conducted should also be provided.
A data collection course provides a standardized means of collecting information from eligible studies. For a meta-analysis of correlational data, effect size information is usually collected as Pearson's r statistic. Partial correlations are oft reported in inquiry, even so, these may inflate relationships in comparison to zero-social club correlations (Cramer, 2003). Moreover, the partialed out variables volition likely vary from report-to-study. Every bit a effect, many meta-analyses exclude partial correlations from their analysis (e.g., Klassen and Tze, 2014; Jim et al., 2015; Slaughter et al., 2015). Thus, written report authors should exist contacted to provide missing information or zero-gild correlations. As a final resort, plot digitizers (e.g., Gross et al., 2014) can be used to scrape data points from scatterplots (if bachelor) for the calculation of Pearson's r. Data reporting important written report characteristics that may moderate furnishings, such as the hateful age of participants, should besides exist collected. Piloting the information required by randomly selecting a few eligible studies during the early stages of meta-analysis planning volition help refine the form. A measure out of study quality can as well be included in these forms to assess the quality of evidence from each written report. There are more than eighty tools bachelor to assess the quality and risk of bias in observational studies (Sanderson et al., 2007) reflecting the diverseness of research approaches between fields. These tools unremarkably include an assessment of how dependent variables were measured, appropriate selection of participants, and advisable control for misreckoning factors. Other quality measures that may exist more relevant for correlational studies include sample size, psychometric properties, and reporting of methods. In many cases, such as the example meta-analysis used in this paper (Molloy et al., 2014), a bespoke quality tool is adult integrating diverse criteria suited to the meta-assay research question. Forth with providing a measure of overall take chances of bias – which is ane of the checklist items in PRISMA – this tin can as well be assessed as a moderator for the meta-analysis.
A final consideration is whether to include studies from the gray literature, which is defined as research that has not been formally published. This type of literature includes briefing abstracts, dissertations, and pre-prints. While the inclusion of gray literature reduces the risk of publication bias, the methodological quality of the work is often (only not always) lower than formally published work (Egger et al., 2003). Reports from conference proceedings, which are the most common source of grayness literature (McAuley et al., 2000), are poorly reported (Hopewell and Clarke, 2005) and information in the subsequent publication is oftentimes inconsistent, with differences observed in almost twenty% of published studies (Bhandari et al., 2002). The meta-analyst needs to consider the main sources of where they expect studies to reside. While the gray literature has been traditionally difficult to access in some cases, it is becoming increasingly accessible with many universities now posting dissertations in online repositories. Thus, the advantages and disadvantages of including greyness literature need to be considered. Differences betwixt fields and inquiry questions preclude any blanket recommendations. Regardless, meta-analyses should explicitly item search strategy in the written report protocol and methods.
Assay
Various tools are available for performing a meta-analysis, such every bit Comprehensive Meta-Analysis (Borenstein et al., 2005) and SPSS syntax files (Field and Gillett, 2010). For this review, I volition use the "metafor" (Viechtbauer, 2010) and "robumeta" (Fisher and Tipton, 2015) packages for R (R Evolution Core Team, 2015). R is an ideal software package to perform meta-analyses considering information technology is freely available and the scripts used can be hands shared and reproduced. For illustration, data from a meta-analysis of sixteen studies (Molloy et al., 2014) that investigate the clan between conscientiousness and medication adherence will be analyzed (Table 1). The dataset includes correlations, study sample sizes, and a range of continuous (due east.g., mean historic period) and chiselled variables (e.chiliad., type of conscientiousness measure used) that can assessed every bit potential moderators. The information from this meta-analysis, forth with analysis examples, are included in the metafor package (Viechtbauer, 2010). The script associated with this paper (also bachelor at: http://github.com/dsquintana/corr_meta) details all aspects of the analysis described herein, which readers can adapt to perform their own meta-analyses of correlational information.

TABLE ane. Instance meta-analysis information (Molloy et al., 2014).
The offset analysis step is entering data from collection forms into a .csv file for analysis in R. As Pearson's r is non unremarkably distributed, these values are converted into Fisher's z scale. Nonetheless, before the meta-analysis can be performed, the meta-analysis model needs to be specified. Two models are commonly adopted in meta-assay: the fixed- and random-effects models. The selection of these models center around assumptions of study homogeneity, that is, how much of the variation of studies can exist attributed to variation in the true effect sizes. Variation is derived from both random error and true study heterogeneity. The fixed-effects model assumes that all studies are from a unmarried common population, tested under like conditions. For example, a series of studies done in the same laboratory, cartoon from the same population may authorize for the fixed-effects model. As the fixed-effects model does not account for study heterogeneity, it can overestimate the summary effect sizes if studies are non drawn from the same population. Thus, if studies are drawn from different populations, the random-furnishings model should be used. The random-furnishings model also provides less study weight to larger studies with less variance. As a result, the calculated confidence interval (CI) is much wider than the CI that would be generated by using a fixed-furnishings model. Even if the random-effects model is applied to homogenous studies, it volition summate a CI equivalent to the fixed-furnishings model. After performing the meta-analytic calculations, Fisher's z should exist converted back to Pearson'due south r to for reporting the boilerplate correlation and 95% CI. Performing the analysis of the example information reveals a summary correlation and 95% CI indicative of a significant, simply modest, relationship betwixt conscientiousness and medication adherence [r = 0.15; 95% CI (0.09, 0.21), p < 0.0001].
Study Heterogeneity
There are 2 sources of variation in observed effects: within-report error and real heterogeneity in effect size. For the purposes of meta-assay we are interested in the true heterogeneity in effect sizes. Calculating the Q-statistic, which is the ratio of observed variation to within-study variance, can reveal how much of the overall heterogeneity tin can be attributed to truthful between-studies variation. The Q-statistic is a null hypothesis significance test (NHST) that evaluates the cypher hypothesis that all studies are examining the same effect. Consequently, a statistically significant Q-statistic indicates that the included studies practise not share a mutual effect size. Similar any other NHST, however, a non-meaning Q-statistic does not provide prove that studies are homogeneous. Further, the Q-statistic is prone to underestimating heterogeneity in small samples and overestimating for large samples (Higgins et al., 2003). The related I ii statistic is a percentage that represents the proportion of observed variation that can be attributed to the actual deviation between studies, rather than within-report variance. I 2 thresholds have been proposed (Higgins et al., 2003), with 25, 50, and 75% representing low, moderate, and high variance, respectively. The two main advantages of I two, compared to the Q-statistic, are that information technology is not sensitive to the number of studies included and that CIs tin also be calculated. Meta-analyses comprising heterogeneous studies provide less weight to larger studies with smaller variance. Tau-squared tin also be used to estimate the total amount of study heterogeneity in random-effects models. When Tau-squared is zero this is indicative of no heterogeneity. In the example data, I 2 was 61.73% (95% CI; 25.28, 88.25) – which represents moderate-to-high variance – the Q-statistic was 38.16 (p = 0.001), and tau-squared was 0.008 (95% CI; 0.002, 0.038).
Although these tests provide evidence for heterogeneity, they do not provide any indication of which studies that may be disproportionately influencing heterogeneity. Baujat et al. (2002) take proposed a plot to identify studies that excessively contribute to heterogeneity and the overall result. The plot's horizontal centrality illustrates study heterogeneity whereas the vertical axis illustrates the influence of a study on the overall effect. Studies that fall to the height correct quadrant of the plot contribute most to both these factors. Examining the Bajaut plot generated from the example dataset reveals three studies that contribute to both of these factors (Figure 3). A closer look at the characteristics of these studies may reveal moderating variables that contribute to heterogeneity. A set of diagnostics derived from standard linear regression are also bachelor within the metafor package to place potential outliers and influential cases, which can also influence observed heterogeneity (Viechtbauer and Cheung, 2010). None of the studies in the example dataset were identified as potential outliers.
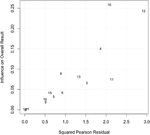
FIGURE three. Baujat plot to identify studies contributing to heterogeneity. Each study is represented by a study id number. Studies located in the elevation right quadrant have both a greater influence on the overall consequence and contribute most to study heterogeneity.
Forest Plots
Forest plots visualize the effect sizes and CIs from the included studies, along with the computed summary effect size. Figure 4 illustrates the forest plot calculated from the example information. Each written report is represented past a point estimate, which is bounded by a CI for the issue. The summary effect size is represented by the polygon at the bottom of the plot, with the width of the polygon representing the 95% CI. Consistent with the high I 2 and pregnant Q-statistic, the forest plot illustrates a sample of heterogeneous studies. Studies with larger squares accept contributed more to the summary event size compared to other studies. In a random-effects model, the size of the square is related to both the CI and between-studies variance.

Figure 4. Forest plot of case information. Summary of instance data investigating the human relationship between conscientiousness and medication adherence. Each report included in the meta-analysis is represented by a point judge, which is bounded by a 95% CI. The summary issue size is displayed as a polygon at the bottom of the plot, with the width of the polygon representing the 95% CI.
Publication Bias
Publication bias is the phenomenon whereby studies with stronger furnishings sizes are more likely to be published and subsequently included in a meta-assay. A funnel plot is a visual tool used to examine potential publication bias in meta-analyses. These plots illustrate the private effect sizes on the horizontal axis and corresponding standard errors on the vertical axis. Studies with smaller standard errors (usually larger studies) prevarication closer to the summit of the plot. The funnel lines are centerd on the summary outcome size, represented by the vertical line, and point the degree of spread that would exist expected for a given level of standard error. In other words, the effect size of a study with low standard error would not be expected to stray very far from the vertical line. As the vertical line represents the summary of all the studies, these points should exist equivalently spread on both sides of the line (Figure 5A). Publication bias dictates that studies with non-pregnant results are less likely to be published. Consequently, if a significant positive effect were institute for the summary upshot size, for instance, the vertical line would exist situated to the correct of aught. Whatever study with a non-significant effect would lie around zero, thus if the funnel is uneven with more than positively associated studies to the right of the line this provides evidence for publication bias. Effigy 5B illustrates this using a simulation of removing three studies from the example dataset. It is important to notation that studies ofttimes report a meaning negative association. If this were the case then missing studies would be situated to the right of the vertical line. Although funnel plots provide a useful visualization for potential publication bias, information technology is important to consider that disproportion may reflect other types of bias, such as study quality, location bias, and study size (Egger et al., 1997).

FIGURE 5. Funnel plots to illustrate publication bias. Funnel plot (A) includes all 16 studies from Molloy et al. (2014). This plot illustrates symmetry (i.due east., points fall on both sides of the summary effect size). Egger's regression test (p = 0.31) was consistent with this information, as the p-value was to a higher place 0.05. Funnel plot (B) simulates the removal of three studies with small issue sizes and large standard mistake from the Molloy et al. (2014) dataset. The plot is no longer symmetrical, demonstrating testify of publication bias. Egger's regression exam (p = 0.01) was besides consistent with this data, every bit the p-value was below 0.05. The trim and fill procedure imputes missing studies (hollow circles) to create a more symmetrical funnel plot (C).
Another weakness of funnel plots is that they only offer a subjective measure of potential publication bias. Two tests are often employed to summate an objective measure out of potential bias. The rank correlation test (Begg and Mazumdar, 1994) evaluates if event estimates and sampling variances for each report are related. A pregnant test (p < 0.05) is consequent with a not-symmetrical funnel plot. Still, the rank correlation test may only have moderate ability for smaller meta-assay (Begg and Mazumdar, 1994; Sterne et al., 2000). An alternative exam that is better suited to smaller meta-analyses (<25 studies) is Egger'south regression exam (Egger et al., 1997).
In the instance data, neither the rank correlation (p = 0.39) nor Egger'due south regression test (p = 0.31) were statistically pregnant, which is consequent with funnel plot symmetry. However, in the false "biased" dataset (see Supplementary Material), the rank correction (p = 0.01) and regression (p = 0.001) tests were statistically significant, consistent with funnel plot disproportion and potential publication bias. If there is evidence of publication bias, the trim and fill method tin can be used (Duval and Tweedie, 2000). This method, which assumes that funnel plot asymmetry is due to publication bias, adjusts a meta-analysis by imputing "missing" studies to increment funnel plot symmetry (Figure 5C). This updated meta-analysis with imputed studies should not be used to form conclusions – as these are not real studies – just as an effort to balance out asymmetrical funnel plots. A comparison of Figures 5A,C illustrates this as the method is designed to only guess the missing studies by creating a mirror image of the existing studies. Consistent with prior piece of work (Pham et al., 2001), the trim and fill up method using the electric current data provides a reasonable judge of how many studies are missing – bold that the studies in the example meta-analysis represent all existing studies. As shown previously (Terrin et al., 2003), the trim and fill method may slightly overestimate missing studies (four studies were removed, simply 5 were imputed). Nevertheless, the method tin exist used a class of sensitivity assay to assess the potential impact of these probable studies on the summary effect size.
Moderator Analysis
Moderating variables contribute to some of the observed variance. Thus, a moderator analysis can be conducted to make up one's mind the source of heterogeneity and how much this contributes to the observed variability of effect sizes between studies. Moderating variables can either be continuous or categorical variables. For instance, a moderator analysis using a meta-regression model can be conducted to examine the influence of hateful age on the Molloy et al. (2014) dataset. Calculating this analysis reveals that age did not have a moderating effect [Q(1) = 1.43, p = 0.23]. Additionally, the moderating effect of methodological quality can exist examined. Analysis of the instance information indicated that methodological quality also did non moderate the correlation [Q(1) = 0.64, p = 0.42]. However, moderator assay suggests that the variable categorizing whether studies decision-making for variables (yep/no) was a pregnant moderator [Q(1) = twenty.12, p < 0.0001]. While there may be other unidentified sources of written report heterogeneity, the information bespeak that controlling for variables within studies contributes to the overall observed heterogeneity.
Accounting for Multiple Outcome Sizes from Individual Studies
If more than one ready of information has been collected from the aforementioned study, the within-subject statistical dependency of these event sizes should exist deemed for due to issues of statistical dependency (Hunter and Schmidt, 2004). There are a number of approaches to this outcome. The most straightforward process is to but collect i effect size per study using pre-specified criteria (e.g., Chalmers et al., 2014; Alvares et al., in press). Alternatively, issue sizes can be aggregated (Encounter the 'Agg' function in the 'MAc' R packet; Del Re and Hoyt, 2010). Nevertheless, without reported within-written report correlations, the researcher has to judge a level of expected correlations. Robust variance estimation (RVE) tin business relationship for non-independent sizes without knowledge of inside-study correlations (Hedges et al., 2010). RVE estimators can likewise be adjusted to better accommodate smaller meta-analyses (n < twoscore; Tipton, 2015). To illustrate the use of RVE to handle multiple outcome sizes, a new simulated dataset has been created with the first three studies from the sample information set treated equally if they were three effect sizes reported from a single written report (see Supplementary Cloth). Analysis using RVE reveals a statistically significant point estimate [0.xv; 95% CI (0.08, 0.22), p = 0.001]
Information Interpretation and Reporting
The final step of a meta-analysis is information interpretation and write-up. The PRISMA guidelines provide a checklist that includes all the items that should be included when reporting a meta-analysis (Moher et al., 2009). Following this checklist will help ensure the quality of reporting meta-analysis and facilitate improved evaluation of manuscripts. An important signal for moderator analysis is that results are not over-interpreted. For instance, performing a moderator analysis of the effect of gender may reveal a difference, however, there could other unidentified written report characteristics that can better explain the moderating furnishings. In other words, moderator assay does not specifically target a single variable, only rather, a set of studies that happen to share that variable. Relatedly, the absence of a statistically significant result does not provide testify for the null hypothesis (i.eastward., that there is no relationship betwixt two variables). Thus, caution is required when interpreting non-significant summary effect sizes. Finally, the R script used for analysis can as well be provided as supplementary textile to aid reproducibility.
General Discussion
The purpose of this commodity is to provide a not-technical primer for conducting meta-analyses of correlational data, following gold-standard guidelines. Meta-analysis is an effective method to synthesize data, which can meaningfully increase statistical precision fifty-fifty from every bit picayune equally two or iii studies. Although meta-assay is a valuable tool, it is seldom taught in undergraduate statistics courses (Cumming, 2006). This paper demonstrates each step of the analysis for researchers that are unfamiliar with meta-analytic methods, using freely attainable software. The supplementary script provides the necessary code to bear out the analyses described in the paper. Methods for data visualization, identifying studies that may be excessively influencing sample heterogeneity, and combining multiple effect sizes from individual studies are also discussed. Some caveats for meta-analysis data interpretation in regards to publication bias and moderator analysis are also described. I have limited this article to correlational studies for the sake of brevity and focus. Hereafter research would benefit from similar non-technical primers with supplementary scripts on other types of effect sizes, such as F or t-tests. However, other than the assay section, this newspaper is broadly applicable for the meta-analysis of other effect size types.
Up to 63% of psychological scientists anonymously admit to questionable research practices (John et al., 2012). These practices include removing information points and reanalysing data, failing to report all measures analyzed, and HARKing. Such behavior has likely contributed to the low rates of successful replication observed in psychology (Open up Science Collaboration, 2015). The pre-registration of clinical trial protocols has become standard. In dissimilarity, less than 10% of meta-analyses refer to a study protocol, allow alone make the protocols publically available (Moher et al., 2007). Thus, meta-analyses pre-registration would markedly meliorate the transparency of meta-analyses and the conviction of reported findings.
Conflict of Interest Argument
The author declares that the research was conducted in the absence of any commercial or financial relationships that could exist construed as a potential conflict of interest.
Acknowledgments
Thanks to James Heathers for providing comments on an before version of the manuscript and to the reviewers of this manuscript for their constructive comments.
Supplementary Material
The Supplementary Material for this article can be found online at: https://world wide web.frontiersin.org/article/10.3389/fpsyg.2015.01549
Footnotes
- ^http://www.crd.york.air conditioning.uk/PROSPERO/
- ^http://www.campbellcollaboration.org/int_dev_our_group/how_to_register.php
- ^http://community.cochrane.org/cochrane-reviews/proposing-new-reviews.
References
Alvares, G. A., Quintana, D. S., Hickie, I. B., and Guastella, A. J. (in printing). Autonomic nervous system dysfunction in psychiatric disorders and the touch of psychotropic medications: a systematic review and meta-analysis. J. Psychiatry Neurosci.
PubMed Abstruse | Google Scholar
APA Publications and Communications Board Working Group on Journal Article Reporting Standards (2008). Reporting standards for enquiry in psychology: why practise nosotros need them? What might they be? Am. Psychol. 63, 839–851. doi: 10.1037/0003-066X.63.9.839
PubMed Abstract | CrossRef Full Text | Google Scholar
Baujat, B., Mah, C. D., Pignon, J.-P., and Hill, C. (2002). A graphical method for exploring heterogeneity in meta-analyses: application to a meta-analysis of 65 trials. Stat. Med. 21, 2641–2652. doi: 10.1002/sim.1221
PubMed Abstract | CrossRef Total Text | Google Scholar
Bhandari, M., Devereaux, P. J., Guyatt, Yard. H., Cook, D. J., Swiontkowski, Yard. F., Sprague, S., et al. (2002). An observational report of orthopaedic abstracts and subsequent total-text publications. J. Bone Joint Surg. Am. 84-A, 615–621.
Google Scholar
Borenstein, M., Hedges, L., Higgins, J., and Rothstein, H. (2005). Comprehensive Meta-Analysis Version 2. (Englewood, NJ: Biostat), 104.
Google Scholar
Bornmann, Fifty., and Mutz, R. (2015). Growth rates of modern scientific discipline: a bibliometric analysis based on the number of publications and cited references. J. Assoc. Inf. Sci. Technol. doi: 10.1002/asi.23329
CrossRef Full Text | Google Scholar
Chalmers, J., Quintana, D. South., Abbott, M. J., and Kemp, A. H. (2014). Anxiety disorders are associated with reduced centre charge per unit variability: a meta-analysis. Front. Psychiatry 5:80. doi: 10.3389/fpsyt.2014.00080
PubMed Abstract | CrossRef Full Text | Google Scholar
Cooper, H. (2009). Research Synthesis and Meta-Analysis: A Step-past-Step Arroyo. Thou oaks, CA: Sage Publications.
Google Scholar
Counsell, C. (1997). Formulating questions and locating chief studies for inclusion in systematic reviews. Ann. Intern. Med. 127, 380–387. doi: 10.7326/0003-4819-127-5-199709010-00008
PubMed Abstract | CrossRef Total Text | Google Scholar
Cumming, G. (2006). "Meta-analysis: pictures that explain how experimental findings can exist integrated," in Proceedings of the Seventh International Conference on Teaching Statistics, Salvador, 1–four.
Google Scholar
Duval, S., and Tweedie, R. (2000). Trim and fill: a simple funnel-plot-based method of testing and adjusting for publication bias in meta-analysis. Biometrics 56, 455–463. doi: ten.1111/j.0006-341X.2000.00455.10
PubMed Abstract | CrossRef Full Text | Google Scholar
Dwan, Chiliad., Altman, D. G., Cresswell, 50., Blundell, Thousand., Take chances, C. L., Williamson, P. R. (2011). Comparison of protocols and registry entries to published reports for randomised controlled trials. Cochrane Database Syst. Rev. 1:MR000031. doi: ten.1002/14651858.MR000031.pub2
PubMed Abstract | CrossRef Full Text | Google Scholar
Egger, M., Davey Smith, G., Schneider, 1000., and Minder, C. (1997). Bias in meta-analysis detected past a uncomplicated, graphical test. BMJ 315, 629–634. doi: x.1136/bmj.315.7109.629
CrossRef Total Text | Google Scholar
Egger, M., Juni, P., Bartlett, C., Holenstein, F., and Sterne, J. (2003). How important are comprehensive literature searches and the assessment of trial quality in systematic reviews? Empirical study. Health Technol. Assess. 7, one–76.
PubMed Abstract | Google Scholar
Hedges, 50. V., Tipton, E., and Johnson, M. C. (2010). Robust variance estimation in meta-regression with dependent effect size estimates. Res. Synth. Methods one, 39–65. doi: x.1002/jrsm.5
PubMed Abstract | CrossRef Full Text | Google Scholar
Hopewell, S., and Clarke, K. (2005). Abstracts presented at the American Society of Clinical Oncology conference: how completely are trials reported? Clin. Trials 2, 265–268. doi: 10.1191/1740774505cnO9loa
PubMed Abstract | CrossRef Full Text | Google Scholar
Hunter, J. Due east., and Schmidt, F. L. (2004). "Methods of meta-assay," in Correcting Error and Bias in Research Findings, 2nd Edn, eds J. E. Hunter and F. L. Schmidt (Chiliad Oaks, CA: SAGE Publications).
Google Scholar
Jim, H. S., Pustejovsky, J. E., Park, C. L., Danhauer, South. C., Sherman, A. C., Fitchett, Chiliad., et al. (2015). Faith, spirituality, and physical wellness in cancer patients: a meta-assay. Cancer doi: 10.1002/cncr.29353 [Epub alee of impress].
PubMed Abstract | CrossRef Total Text | Google Scholar
John, Fifty. K., Loewenstein, Grand., and Prelec, D. (2012). Measuring the prevalence of questionable inquiry practices with incentives for truth telling. Psychol. Sci. 23, 524–532. doi: 10.1177/0956797611430953
PubMed Abstruse | CrossRef Full Text | Google Scholar
Klassen, R. 1000., and Tze, V. Yard. (2014). Teachers' self-efficacy, personality, and instruction effectiveness: a meta-analysis. Educ. Res. Rev. 12, 59–76. doi: 10.1016/j.edurev.2014.06.001
CrossRef Full Text | Google Scholar
Lipsey, M. W., and Wilson, D. B. (2001). Practical Meta-analysis. G Oaks, CA: Sage publications.
Google Scholar
McAuley, L., Pham, B., Tugwell, P., and Moher, D. (2000). Does the inclusion of grey literature influence estimates of intervention effectiveness reported in meta-analyses? Lancet 356, 1228–1231. doi: 10.1016/S0140-6736(00)02786-0
PubMed Abstract | CrossRef Full Text | Google Scholar
Moher, D., Liberati, A., Tetzlaff, J., Altman, D. One thousand., and Prisma Group. (2009). Preferred reporting items for systematic reviews and meta-analyses: the PRISMA statement. PLoS Med. 6:e1000097. doi: 10.1371/journal.pmed.1000097
PubMed Abstract | CrossRef Total Text | Google Scholar
Moher, D., Tetzlaff, J., Tricco, A. C., Sampson, Thousand., and Altman, D. G. (2007). Epidemiology and reporting characteristics of systematic reviews. PLoS Med. 4:e78. doi: 10.1371/periodical.pmed.0040078
PubMed Abstract | CrossRef Total Text | Google Scholar
Pham, B., Platt, R., McAuley, L., Klassen, T. P., and Moher, D. (2001). Is there a "best" mode to detect and minimize publication bias? An empirical evaluation. Eval. Health Prof. 24, 109–125. doi: 10.1177/016327870102400202
PubMed Abstract | CrossRef Full Text | Google Scholar
R Development Cadre Team (2015). R: A Language and Environment for Statistical Computing. Vienna: The R Foundation for Statistical Computing.
Google Scholar
Sanderson, S., Tatt, I. D., and Higgins, J. P. (2007). Tools for assessing quality and susceptibility to bias in observational studies in epidemiology: a systematic review and annotated bibliography. Int. J. Epidemiol. 36, 666–676. doi: x.1093/ije/dym018
PubMed Abstract | CrossRef Full Text | Google Scholar
Shamseer, L., Moher, D., Clarke, M., Ghersi, D., Liberati, A., Petticrew, M., et al. (2015). Preferred reporting items for systematic review and meta-assay protocols (PRISMA-P) 2015: elaboration and caption. BMJ 349, g7647–g7647. doi: 10.1136/bmj.g7647
PubMed Abstract | CrossRef Full Text | Google Scholar
Slaughter, V., Imuta, K., Peterson, C. C., and Henry, J. D. (2015). Meta-analysis of theory of mind and peer popularity in the preschool and early school years. Child Dev. 86, 1159–1174. doi: x.1111/cdev.12372
PubMed Abstract | CrossRef Full Text | Google Scholar
Sterne, J. A., Gavaghan, D., and Egger, K. (2000). Publication and related bias in meta-analysis: power of statistical tests and prevalence in the literature. J. Clin. Epidemiol. 53, 1119–1129. doi: 10.1016/S0895-4356(00)00242-0
PubMed Abstract | CrossRef Full Text | Google Scholar
Tricco, A. C., Pham, B., Brehaut, J., Tetroe, J., Cappelli, M., Hopewell, Southward., et al. (2009). An international survey indicated that unpublished systematic reviews exist. J. Clin. Epidemiol. 62, 617.e5–623.e5. doi: x.1016/j.jclinepi.2008.09.014
PubMed Abstract | CrossRef Full Text | Google Scholar
Viechtbauer, Due west. (2010). Conducting meta-analyses in R with the metafor package. J. Stat. Softw. 36, 1–43. doi: 10.18637/jss.v036.i03
CrossRef Full Text | Google Scholar
Vincent, B., Vincent, M., and Ferreira, C. Thousand. (2006). Making PubMed searching simple: learning to retrieve medical literature through interactive trouble solving. Oncologist 11, 243–251. doi: ten.1634/theoncologist.11-three-243
PubMed Abstract | CrossRef Full Text | Google Scholar

Source: https://www.frontiersin.org/articles/10.3389/fpsyg.2015.01549/full
Posted by: thompsonsabor1982.blogspot.com
0 Response to "Why Is It Most Important To Pre-register Your Statistical Analyses?"
Post a Comment